May 15, 2026
The content of this blog is based on my prior comedy talk at Purdue University: "All Our TeX Source Are Not Belong to You:" PDF Obfuscation against arXiv's TeX Source Policies
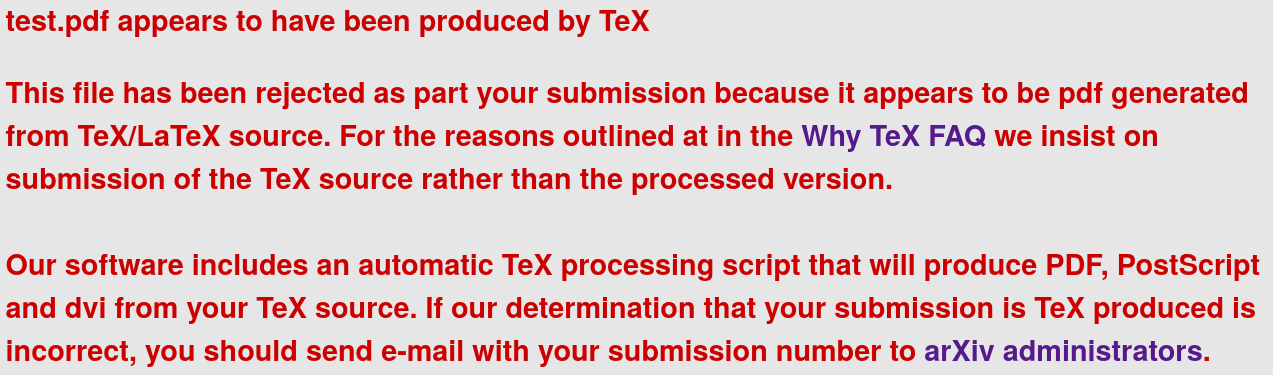
This is an error message from arXiv:
Now, many of you probably don't have the misfortune of seeing this particular error message, because you are using LaTeX and have no trouble of uploading just the LaTeX source code.
As for me, you see, I made the grave mistake several years ago of committing to use LuaLaTeX to format my papers. I don't take full responsibility for that: I was reading Wikipedia at that time, and it claimed LuaLaTeX was the recommended format for LaTeX...
...which says something about not trusting Wikipedia when doing your research, I suppose.
To their credit, LuaLaTeX has helped me out on a few occasions. I was able to format my Japanese linguistics homework thanks to its advanced multilingual support; I was also able to present the mathematical formulae in my paper better by finding the correct font that fits with the body text.
Nevertheless, if I upload the LuaLaTeX source code to arXiv, I get an error message...
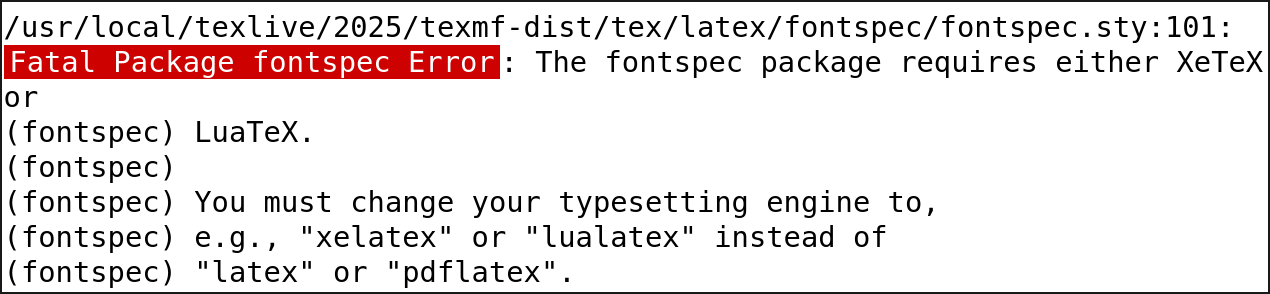
...that literally tells me to use LuaLaTeX.
And, if I dare to upload the compiled PDF...
I get the same error message.
Many people probably would have stopped here, accepted the fact that arXiv seems to really hate LuaLaTeX, and moved on. But, unfortunately, I am a researcher. So I asked the question:
To start with, the metadata from a PDF document seems like a good target:
The many occurrences of "tex" in the metadata is a sweet spot for the detector. But the exact implementation puzzles me.
After all, the University of Texas also has "tex" in its name.
As a busy researcher, I asked one of my friends who happened to be free to upload a bunch of PDFs to see what triggers the detection mechanism.
| Field | Data | Undetected? |
|---|---|---|
/Creator |
TeX |
|
/Creator |
ConTeXt |
|
/Creator |
texture |
|
/Creator |
plaintext |
|
/Creator |
pdfTeXt |
|
/Creator |
texttext
|
|
/Creator |
texttex
|
|
/Creator |
tex-text
|
|
/Creator |
tex |
|
/Creator |
texttex
|
|
/Creator |
ConTeX |
|
/Creator |
TeX* |
|
/Creator |
*TeX |
|
/Creator |
LuaLaTeX |
|
/Creator |
pdfTeXs |
|
/Creator |
texas |
|
/Creator |
TeXas |
|
/Creator |
vertex |
|
/Creator |
paleocoretex |
| Field | Data | Undetected? |
|---|---|---|
/Producer |
pdfTeX-1.40.26 |
|
/Producer |
pdfConTeXt-1.40.26 |
|
/Producer |
texture |
|
/Producer |
plaintext |
|
/Producer |
pdfTeXt |
|
/Producer |
texttext
|
|
/Producer |
texttex
|
|
/Producer |
tex-text
|
|
/Producer |
pdftex-1.40.26 |
|
/Producer |
pdfConTeX-1.40.26 |
|
/Producer |
pdfTeX*-1.40.26 |
|
/Producer |
pdf*TeX-1.40.26 |
|
/Producer |
pdfLuaLaTeX-1.40.26 |
|
/Producer |
TeX |
|
/Producer |
pdfTeXs |
|
/Producer |
texas |
|
/Producer |
TeXas |
|
/Producer |
vertex |
|
/Producer |
paleocoretex |
| Field | Data | Undetected? |
|---|---|---|
/Author |
tex |
|
/CreationDate |
tex |
|
/ModDate |
tex |
|
/PTEX.Fullbanner |
tex |
|
/Subject |
tex |
|
/Title |
tex |
|
/Trapped |
tex |
It turns out that arXiv will block any "tex" in the Creator or Producer field that is not "text," and will absolutely block the University of Texas as the Creator of the PDF as their university name contains "tex." My friend, who studied there, really should have sued them for discrimination.
Fortunately, all the metadata of a PDF can be wiped clean with a short Python script, generated by ChatGPT:
That used to be the end of the story, until someone on Stack Overflow complained that arXiv had enforced additional detections.
Now, if you are reading this blog, you probably can tell that I know a little bit more about TeX than an average person. At that time, I was trying to think what additional measures could have been enforced by arXiv, whose detector, based on the previous analysis, seemed to operate at roughly the level of banning the University of Texas as the creator of a file. They are probably not doing rocket science.
One thing caught my eyes pretty quickly: the font.
To do a quick walkthrough, your research paper can be rendered in a variety of different fonts depending on the template setting, and these are the three more common fonts you will see online.

The first one, Computer Modern Roman (CMR), is the default font used by TeX. It gives a unique spread-out feeling compared to other fonts, and also tend to be a bit thinner.

The second one, Times, is typically seen in IEEE papers and other IEEE-like templates in computer science. It's probably the most common font in use.

The third one, Palatino, is typically seen in ACM papers. It is usually typeset in a small font size in the ACM template and as a result can be hard to read.
All the fonts in a PDF file can be easily extracted and analyzed:
Since CMR is almost exclusively used in TeX, it makes sense that someone who bans the University of Texas will also ban it. I quickly ran a test.
| Field | Data | Undetected? |
|---|---|---|
Font's FontName |
QMHNZG+CMR10 |
|
Font's FamilyName |
Computer Modern |
|
Font's FullName |
CMR10 |
|
/FontName |
/QMHNZG+CMR10 |
|
/BaseFont |
/QMHNZG+CMR10 |
|
/BaseFont |
/QMHNZG+CMMI10 |
|
/BaseFont |
/QMHNZG+CMBX10 |
It turns out that arXiv will only reject a paper if one of its fonts' "BaseFont" field contains "CMR," which is a little looser than I expected. To scrub a font's metadata off is a little more complicated, but there is nothing that ChatGPT cannot handle:
It turns out that this little script just works, and now we can completely bypass arXiv's TeX detection!
We can probably write a pretty decent Stack Overflow answer based on the above research, but as a security researcher, one more interesting question would be:
And the answer to that, I think, is an emphatic no.
Just to illustrate the point, let us consider Typst, another typesetting engine similar to TeX. I quickly built one test PDF from each engine, and looked into their structure:
There are certainly differences in how these engines format their PDF content streams. But if an obfuscator can translate one style of PDF into another while preserving the rendered document, then those differences are conventions, not reliable evidence of origin. In an adversarial setting, detecting TeX-generated PDFs from the PDF alone is therefore not a sound goal.
So we prototyped that with the help of ChatGPT: https://github.com/zhtluo/arxiv-scripts/.
Admittedly, this early prototype does not handle many aspects of PDF that can be encountered in real life, and, to be frank, is probably no more than a toy example on the test PDF. But I think the possibility highly suggests that with enough effort such an obfuscator can be made, and thus, there is no fundamental difference between TeX-generated PDFs and other PDFs.
At this point, it seems certain to me that the current arXiv detection mechanism is flawed; the goal is fundamentally unsound; it raises serious privacy risks (entire X account used to exist to publish any comments it found in arXiv TeX source files); and it also exposes all the TeX code to AI for training for seemingly no particular reason. Hence, it seems to me that I should do something.
I aspire to be a responsible researcher, and I don't want to just randomly publish exploits to the public. So I contacted arXiv first to see if they thought it was a vulnerability that they should do something about.
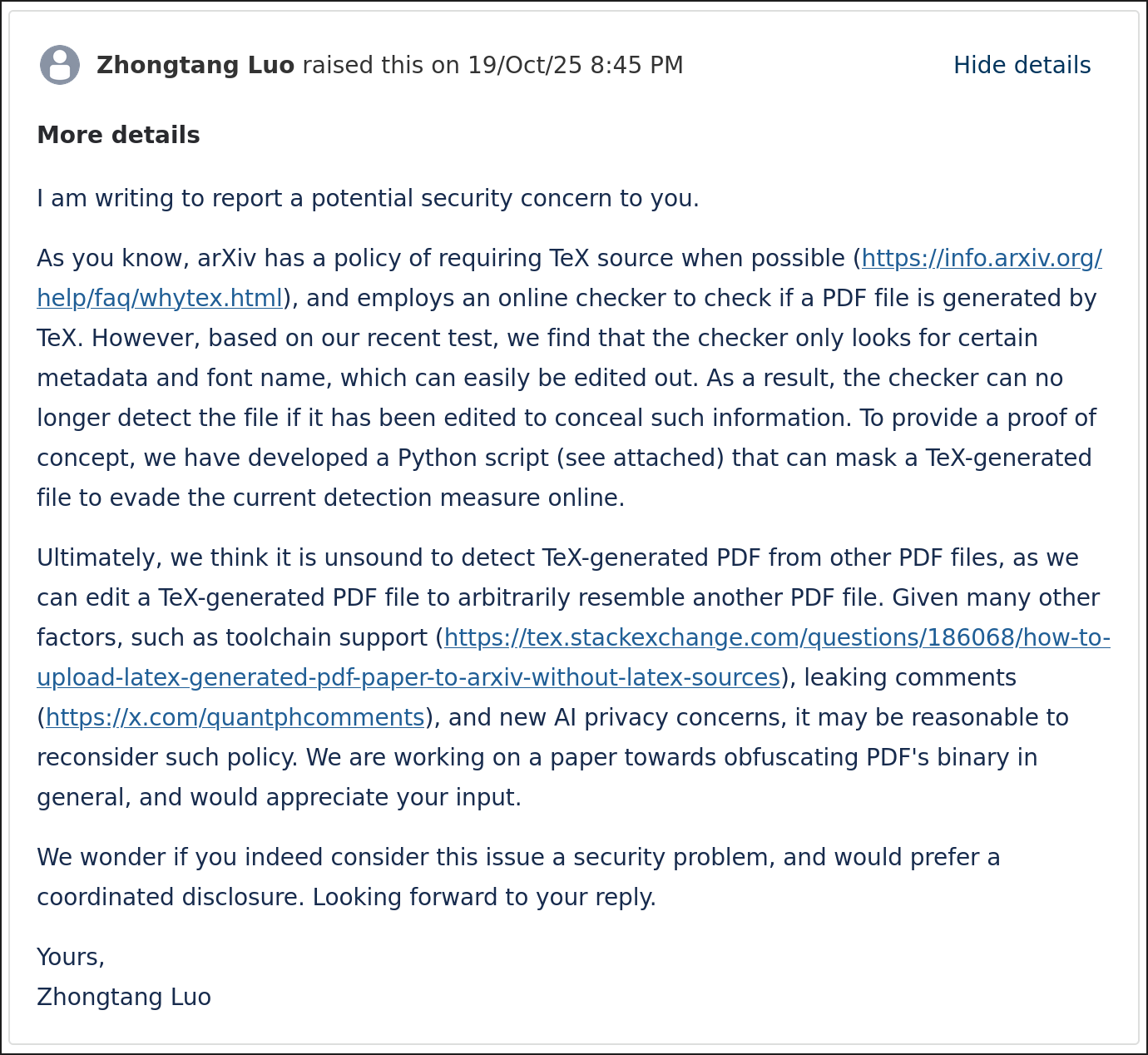
The ever-helpful moderator returned and told me that they didn't think it was a security issue.
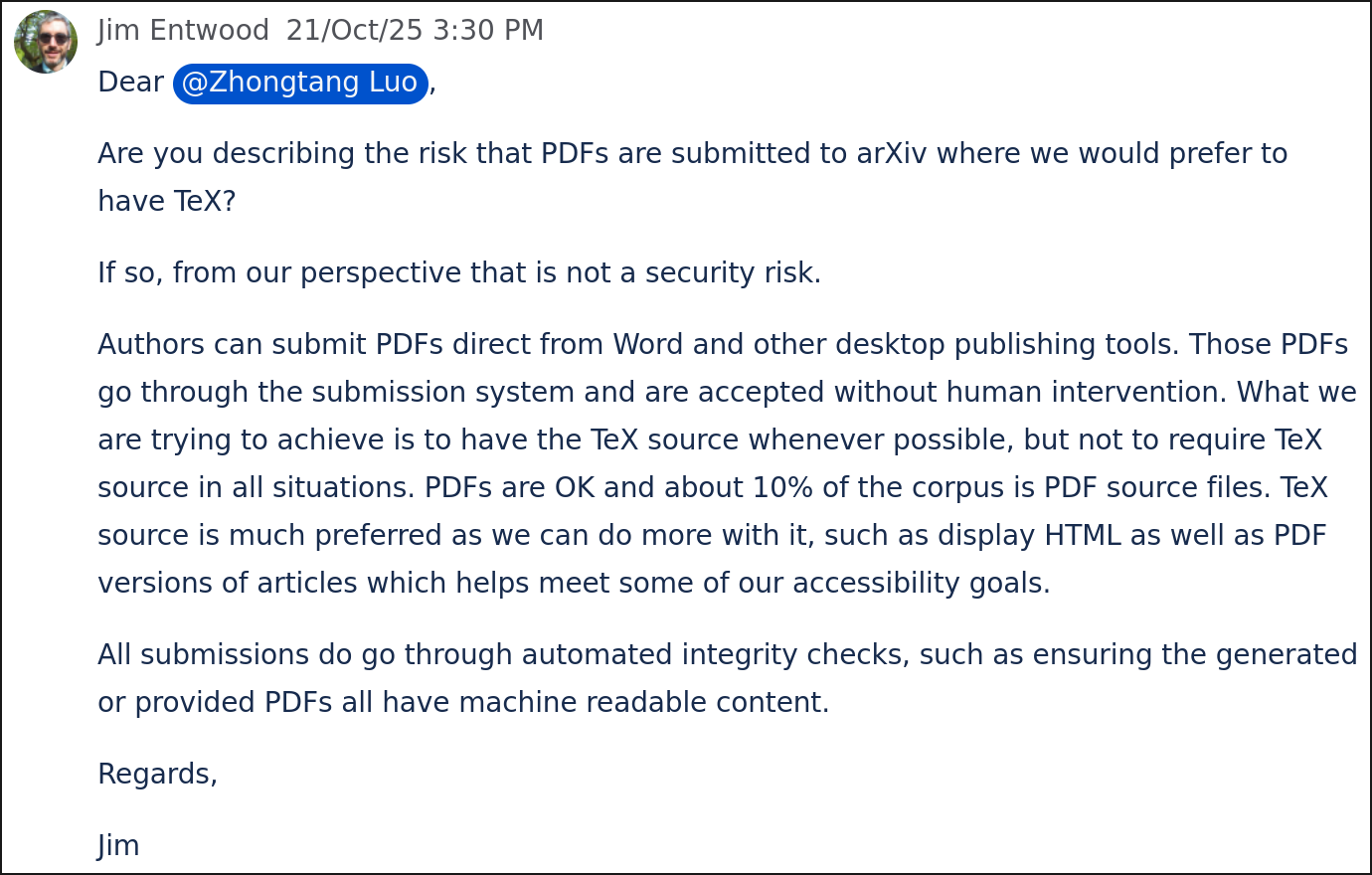
Then, unfortunately, I made the second grave mistake in my life...
...of actually trying to write this discovery into a paper and publish it on arXiv.

I was very quickly contacted by the leadership of arXiv and notified that my paper "is laTeX (sic) generated..."

...when the whole purpose of my paper was that I used LuaLaTeX!
I tried to respectfully write back and tell him of the situation.

...
...
...
And that was the end of our conversation.

I have always thought of myself as a science person, and I believe research should be published because the right to know is a fundamental right. As such, I never quite appreciated the USENIX quote:
When considering ethics, researchers and reviewers must acknowledge that, sometimes, the most ethical path is not to do the research or not to publish the research after it is complete.
Still, watching my paper sit in the portal, awaiting its merciful oblivion, gave me a new and somewhat unwilling appreciation for the quote.

Fortunately, as all researchers know, an important part of research is how you sell it. Hence, instead of trying to sell the research as a security matter, I figured that if I labeled it as obfuscation of the PDF, I might be able to argue that this is a cryptography paper and thus push it to IACR ePrint instead of arXiv.
https://eprint.iacr.org/2026/278
And fortunately, it worked.
So it's probably a good time now to take a look at the paper before someone from arXiv complains that it's not a cryptography paper and gets it taken down. :)